Call us
301-363-4651 (Available 9 a.m. to 5 p.m. CST from Monday to Friday)
Universal Protein Resource (UniProt) comprises the Swiss institute of bioinformatics (SIB), the European institute of bioinformatics (EBI) and the protein information resource (PIR). Its main objective is to provide the scientific community with a central resource for protein sequence and functional information.
SWISS-PROT is a protein sequence database containing detailed annotations. It was established in 1986 and jointly maintained by the department of medical biochemistry of the University of Geneva and the EMBL data library (now EBI) since 1987. The database is currently merged into the UniProt database.
UniProt knowledgebase (UniProtKB) is a comprehensive knowledge base of protein sequences, which consists of two parts: UniProtKB/ SWISS-PROT and UniProtKB/TrEMBL.
All sequence entries in the SWISS-PROT database are carefully verified by experienced molecular biologists and protein chemists through computer tools and related literature.
TrEMBL is a computer-annotated protein sequence database, which is an auxiliary database of SWISS-PROT protein sequence database. This database contains the translation content of all coding sequences (CDS) in EMBL nucleic acid sequence database which has not been incorporated into SWISS-PROT database.
The general structure and retrieval mode of SWISS-PROT and TrEMBL records is consistent. The main difference is that TrEMBL data is "Preliminary", but SWISS-PROT data is "standard".
By the end of 2001, the database contained a total of 102,708 sequence data, including 37,803,202 amino acids.
Regarding the literature, the existing sequence data of the SWISS-PROT database involves 92,845 articles in 1,202 journals. There are 91 journals cited in more than 100 literatures, of which the top 20 journals frequently cited are cited more than 1,000 times. These journals are the main source of literature for publishing protein sequence related information.
In 2001, SWISS-PROT group started the Plant Proteome Annotation Program [1] [2] [3]. The goal of the project is to annotate plant-specific and plant family proteins according to the SWISS-PROT standard [4]. The current focus of the project is to manually annotate the proteome of dicotyledons (Arabidopsis thaliana) and monocotyledons (Oryza sativa).
Compared with other protein databases, SWISS-PROT database differs from other protein sequence databases in three different standards:
SWISS-PROT provides detailed annotation information on protein sequences. Annotation include information on protein function, post-translational modification of proteins, domains and binding sites, secondary structures, quaternary structures, and diseases associated with protein deficiency.
In SWISS-PROT, each entry contains as much relevant literature information as possible, and is integrated. If there is disagreement, it is indicated in the Feature Table.
SWISS-PROT establishes cross-references with a variety of databases databases, such as the protein tertiary structure library PDB, the human gene Mendelian genetic database (MIM), the protein type and the site library (PROSITE), which can directly access related entries in other databases. This extensive and practical database network connection allows users to obtain all aspects of protein information at the same time.
1. Direct access from the UniProt homepage (http://www.uniprot).
2. There are multiple sites on the Web that can access the Swiss-Prot/TrEMBL and retrieve the database. Its main sites are the ExPASy Molecular Biology website (http://www.expasy.org/) and the European Institute of Bioinformatics (EBI) website (http://www.ebi.ac.uk/swissprot/).
ExPASy is one of the main entry points of UniProtKB [5] [6] [7]. Tools in ExPASy can be used to handle several aspects of protein analysis, including BLAST search, proteomics, and sequence analysis, and to consider all splicing variants annotated in UniProtKB. A visual representation of the amino acid characteristic table developed by ExPASy enables users to see the sequence characteristics at a glance.
For more detailed information, please refer to this article [8].
Each entry in SWISS-PROT contains the following information: Known protein sequences, references, taxonomic information, annotations, etc.
The protein entry contains a total of 14 topics.
You can use this database to query some information you need:
The specific content is as follows:
The content of this part is biological knowledge about protein function. In this section, you will get a detailed understanding of the biological functions of proteins and the biological processes in which they are involved. This will help you determine your research direction.
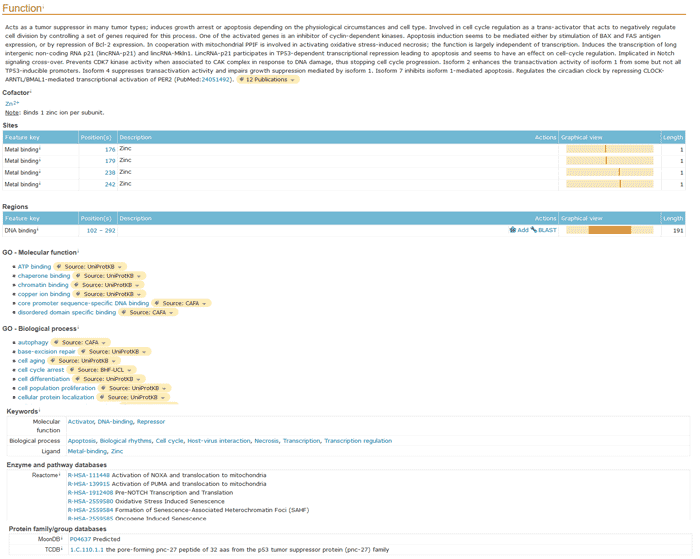
Figure 1 Function section of a UniProtKB entry.
The subsections of this section are:
This section describes the protein name, gene name and classification of the organism.
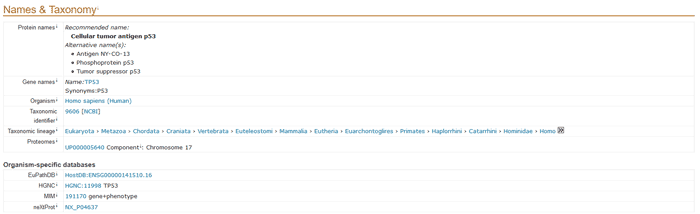
Figure 2 Names & Taxonomy section of a UniProtKB entry.
Here is some information related to the biological knowledge of protein localization and topology. It mainly includes the following contents:
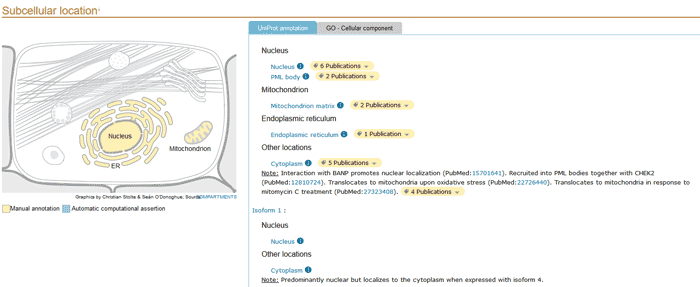
Figure 3 Subcellular location section of a UniProtKB entry.
In the “Topology”, it is possible to distinguish which sequences are extracellular, which are transmembrane, and which are intracellular! This can be used as a reference when studying its different functional segments!

Figure 4 Topology section of a UniProtKB entry.
Knowledge of the biology of disease and the phenotypes associated with protein deficiency.
This section contains the following subsection:

Figure 5 Pathology & Biotech section of a UniProtKB entry.
You can learn about some diseases related to this protein, which should provide a big direction for your research.
If you know the mutation site of your protein sequence, you can query here for the possible functional changes caused by the mutation of this site, as shown in the “description” section.
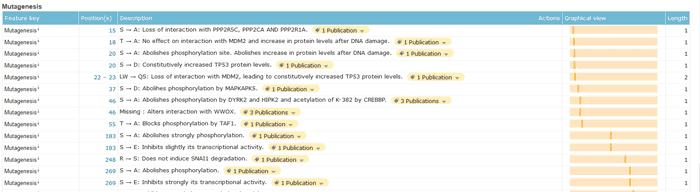
Figure 6 Pathology & Biotech section of a UniProtKB entry.
It includes biological knowledge of post-translational modification of proteins.
The different subsections of the PTM / Processing are:
There's also some information about amino acid modification that you can look at if you're doing epigenetic studies.
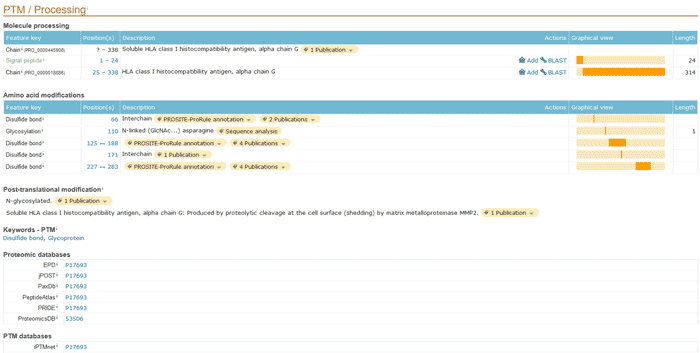
Figure 7 PTM / Processing section of a UniProtKB entry.
It contains information related to the biological knowledge of protein expression.
The different subsections of the expression section are:

Figure 8 Expression section of a UniProtKB entry.
Here is information relevant to the biological knowledge of protein interactions.
The different subsections of the interaction section are:
Information related to the biological knowledge of protein structure.
It includes the following:

Figure 9 Structure section of a UniProtKB entry.
The different subsections of the Family & Domains section are:

Figure 10 Family & Domains section of a UniProtKB entry.
General metadata for a given sequence, such as sequence length, molecular weight, and CRC64 checksum (64-bit cyclic redundancy check value).
The different subsections of the “sequence” are:
You can download the data by click FASTA button. You can also use Align tool to align this entry with its isoforms. Interested proteins can be stored in the basket by clicking the Add to basket button for later comparison or download.
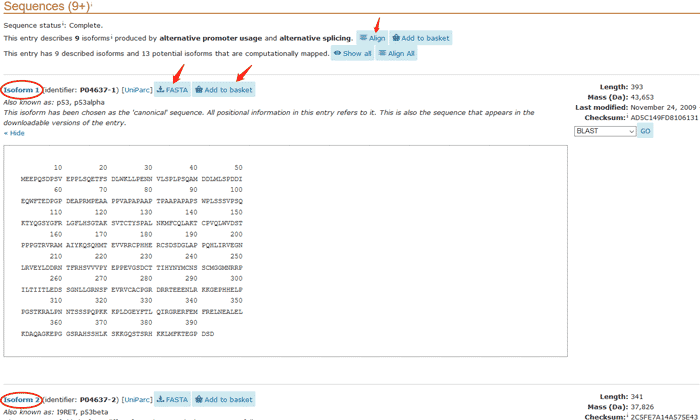
Figure 11 The canonical protein sequence and isoforms
In WB experiments, if the protein size is inconsistent with the predicted size, you can use SWISS-PROT to solve these problems:
First you need to determine whether the protein is endogenous or exogenous and whether it's a full-length sequence.
Query the SWISS-PROT database for other isoforms for this protein.
In the literature of SWISS-PROT, it was found whether there was shear activation of the protein.
Determine whether a protein is a dimer or a polymer.
Search in SWISS-PROT whether there is modification after protein expression, if there is modification will lead to protein increase. This information is available in the “PTMs/Processing” section.
This section provides links to UniRef100, UniRef90 and UniRef50, respectively, corresponding to protein sequences sharing 100%, 90% or 50% identity.
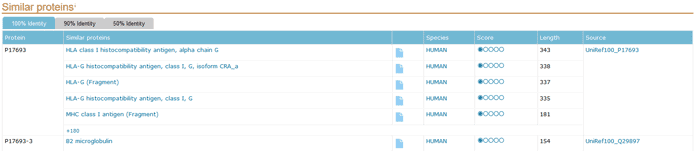
Figure 12 Similar proteins sections of a UniProtKB entry
Cross-referenced sections are organized into subsections by topic. This section links the protein to several other databases that contain information about the protein. Many of these cross links are automatically added to the UniProtKB/ TrEMBL entry, but some are created manually in the UniProtKB/ SWISS-PROT entry.
The cross-reference section contains a variety of different databases:
Sequence databases; 3D structure databases; protein-protein interaction databases; chemistry databases; PTM databases; polymorphism and mutation databases; proteomic databases; protocols and materials databases; genome annotation databases; organism-specific databases; phylogenomic databases; enzyme and pathway databases; miscellaneous databases; gene expression databases; family and domain databases.
In addition to the primary entry number, the protein entry may contain one or more secondary entry numbers, which follow the main entry number.
In SWISSPROT, there are some tools you must know: “Blast”, “Align”, “Retrive/ID mapping”, “Peptide search”.
Blast: With the Basic Local Alignment Search Tool (BLAST), you can find regions of local similarity between sequences, which can be used to infer functional and evolutionary relationships between sequences as well as help identify members of gene families.
Align: Align two or more protein sequences with the Clustal Omega program (see also this FAQ) to view their characteristics alongside each other.
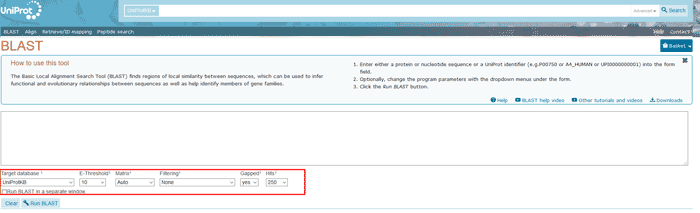
Figure 13 The BLAST tool of UniProt
Set parameters to suit your needs, default settings being: UniProtKB for the data set, 10 for the E-threshold, Matrix auto, no low complexity filtering and gap allowed.
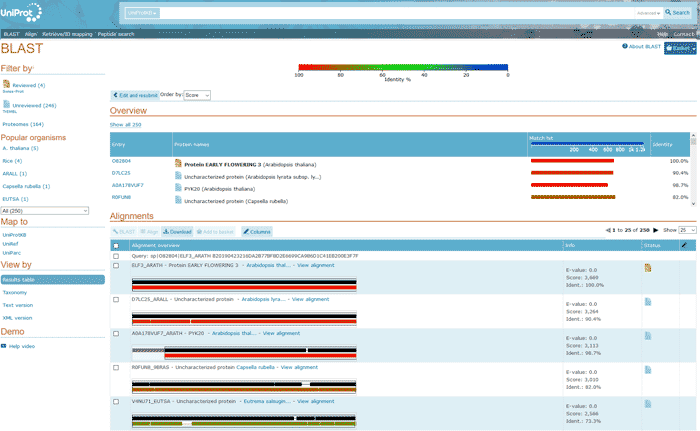
Figure 14 BLAST result
In the BLAST, the detailed list shows the matching proteins. Use different colors to show the identity between the proteins. All proteins are ranked from highest to lowest in identity.
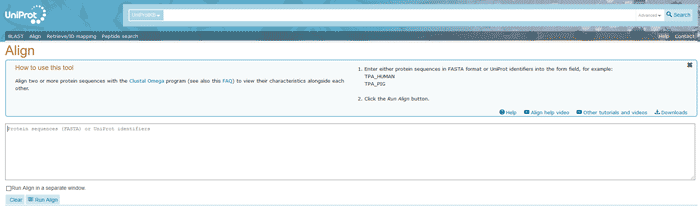
Figure 15 The Align tool of UniProt
The alignment output is interactive and gives the possibility to highlight in different colors sequence features annotated in UniProtKB as well as amino acid properties by selecting properties of interest. When more than two protein sequences are aligned, an alignment tree is also available. Alignment tree gives you an understanding of genetic relationship between these proteins.
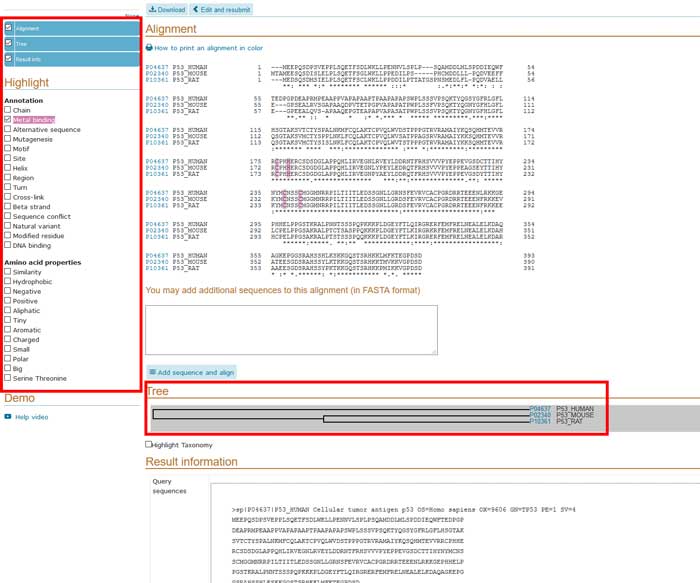
Figure 16 Protein alignment result. Partial view of the protein alignment result made on UniProtKB between P04637, P02340, P10361protein entry.
In the detailed interface of results display, the following contents are included: general information (record name, registration number, etc.), name and source (protein name, etc.), PubMed literature information, comments, cross search, keywords, characteristics, sequence information, etc.
Database Entries can be downloaded in batch. Several sets of protein sequences are proposed for download at http://www.uniprot.org/downloads. A dedicated tool to convert and download a list of proteins is available at http://www.uniprot.org/uploadlists/
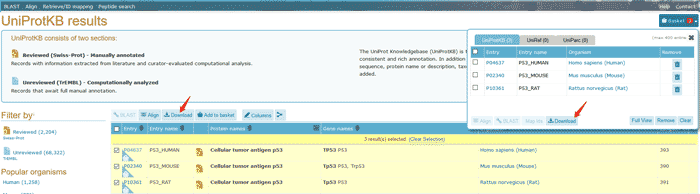
Figure 17 Downloading tool of UniProt
References
[1] Schneider M, Tognolli M, Bairoch A. The Swiss-Prot protein knowledgebase and ExPASy: providing the plant community with high quality proteomic data and tools [J]. Plant Physiology and Biochemistry (Paris), 2004, 42(12): 1013-1021.
[2] Schneider M, Bairoch A, Apweiler W R. Plant Protein Annotation in the Uniprot Knowledgebase [J]. Plant Physiology, 2005, 138(1): 59-66.
[3] Schneider M, Lane L, Boutet E, et al. The UniProtKB/Swiss-Prot knowledgebase and its Plant Proteome Annotation Program [J]. Journal of Proteomics, 2009, 72(3): 567-573.
[4] Boeckmann B. The SWISS-PROT protein knowledgebase and its supplement TrEMBL in 2003 [J]. Nucleic Acids Research, 2003, 31(1): 365-370.
[5] Gasteiger E. ExPASy: the proteomics server for in-depth protein knowledge and analysis [J]. Nucleic Acids Research, 2003, 31(13): 3784-3788.
[6] Walker J M. In The Proteomics Protocols Handbook [M]. Humana Press, 2005.
[7] Gattiker A, Gasteiger E, Bairoch A. ScanProsite: a reference implementation of a PROSITE scanning tool [J]. Applied Bioinformatics, 2002, 1(2): 107.
[8] Boutet E, Lieberherr D, Tognolli M, et al. UniProtKB/Swiss-Prot, the Manually Annotated Section of the UniProt KnowledgeBase: How to Use the Entry View [J]. Methods in Molecular Biology, 2016, 1374: 23-54.


Comments
Leave a Comment