Call us
301-363-4651 (Available 9 a.m. to 5 p.m. CST from Monday to Friday)
Currently, malignant tumor has become one of the causes of death. The incidence of cancer is increasing globally and the age of onset is getting younger.
In 2019, the latest data published by A Cancer Journal For Clinicians shows that the overall cancer death rate in the United States decreased by 27 percent from 1991 to 2016, equivalent to a reduction of about 2.62 million cancer deaths. The report estimates there will be 1,762,450 new cancer cases and 606,888 cancer-related deaths in the United States in 2019.Traditional chemotherapy is a common way to fight cancer, but it attacks the whole body, causing unnecessary side effects such as hair loss, nausea and fatigue.
Targeted therapies selectively kill cancer cells without affecting healthy tissue. Targeted drug development will be an important means to treat cancer.
Figure 1 Tumor targeting therapy
The rapid development of high-throughput assay technology has led to the rapidaccumulation of tumor-related omics data. These data are of great significance for the study of the mechanism of tumor occurrence and development.
How to effectively use and store this information is especially important. The establishment of tumor bioinformatics database provides an effective solution, which has greatly promoted the development of basic tumor research and the improvement of clinical treatment level.
1. Comprehensive Tumor Databases
3. Tumor DNA Methylation Databases
4. Tumor Transcriptome Databases
The following are some tumor-related database classifications and overviews:
The summary of the comprehensive tumor database is shown in table 1.
Table 1 Main features of the 10 human TLR molecules
| Datebase | Description |
|---|---|
| canEvolve | Web portal for integrative oncogenomics |
| cBioPortal | cBioPortal for Cancer Genomics |
| CGAP | Cancer Genome Anatomy Project |
| CGHub | Cancer Genomics Hub |
| CGWB | Cancer Genome Work Bench |
| COSMIC | Catalogue Of Somatic Mutations In Cancer |
| ICGC | International Cancer Genome Consortium |
| TCGA | The Cancer Genome Atlas |
| UCSC Genome Browser | UCSC Cancer Genomics Browser |
The following is a brief overview of the databases:
The information stored in the canEvolve database includes:
Genes, microRNA (miRNA) and protein expression profiles, copy number changes (CNAs) for a variety of cancer types, and protein-protein interaction information.
cBioPortal can be used for interactive exploration of multiple Cancer Genomics data sets. It provides information on CNA and gene mutations.
cBioPortal plays an important role in advancing the research on the discovery of tumor-related mutations, the analysis of biological functions of genes and drug selection.
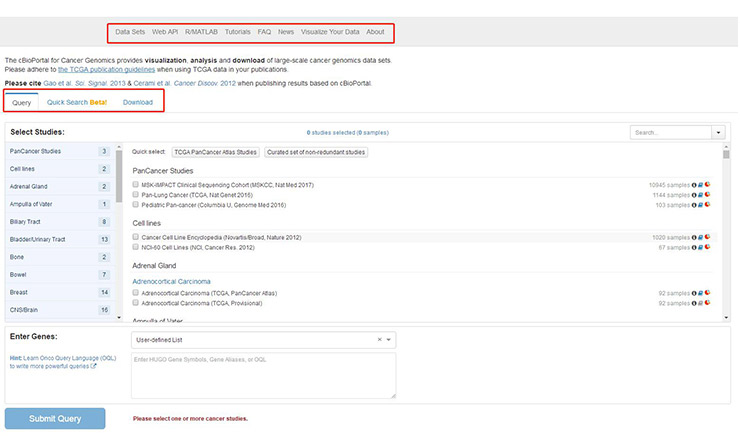
Figure 2 Home page of cBioPortal
CGAP website provides cDNA cloning, libraries, gene expression, SNP, and genomic variation information. Data collected by CGAP include gene expression levels in normal tissues, pre-cancerous tissues, and cancer cells.
The current CGAP program has been extended to include the Tumor Gene Index (TGI), the Genetic Annotation Program (GAI), and the Cancer Chromosome Aberration Program (cCAP).
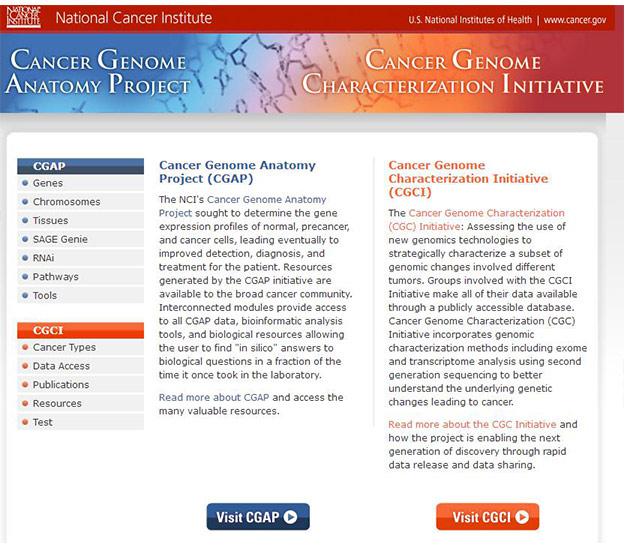
Figure 3 Home page of CGAP
CGHub is an online repository for the national cancer institute (NCI) sequencing program, which includes data from 25 different types of cancer from three national cancer society programs, including The Cancer Genome Atlas (TCGA), the Cancer Cell Line Encyclopedia (CCLE), and the Therapeutically Applicable Research to Generate Effective Treatments (TARGET) projects.
The raw data provided by CGHub plays an important role in integrating and sharing cancer-related data, and plays a significant role in promoting basic cancer research.
CGWB provides a range of tools to mine, integrate, and visualize genomic and clinical data from databases such as TCGA. It is the first computing platform to integrate clinical tumor mutation profiles with reference human genomes. Users can quickly compare patient clinical information with genomic variation and methylation.
COSMIC is the world's largest and most comprehensive source of somatic mutations in tumors and their effects. It mainly provides CNA, methylation, gene fusion, SNP and gene expression information in the genome of various tumor cells.

Figure 4 Home page of COSMIC
ICGC aims to obtain all information on genomes, transcriptomes, and epigenetics of up to 50 tumors and their subtypes including biliary tract cancer, bladder cancer, and blood cancer. These data can promote cancer mechanisms and therapeutic research.
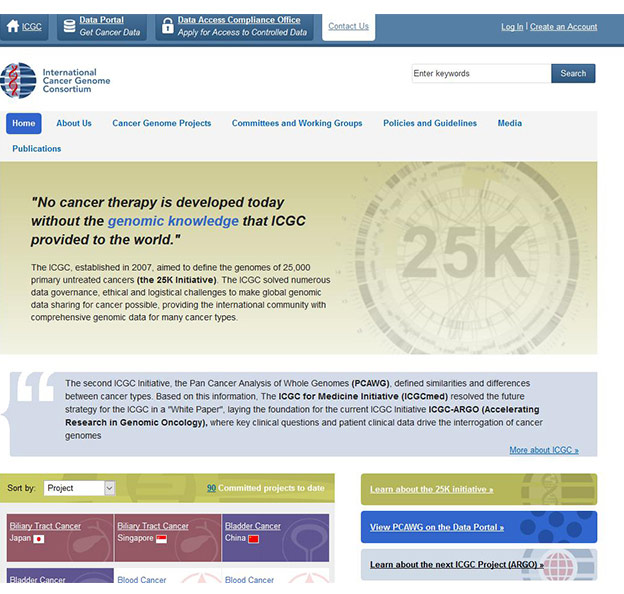
Figure 5 Home page of ICGC
TCGA, funded by the national cancer institute and the national human genome institute, focuses on the molecular map of mutations associated with cancer occurrence and development.
The database mainly performs exome and genome sequencing analysis of the samples, and the data provided include: genome copy number changes, epigenetics, gene expression profiles, miRNAs, and the like.

Figure 6 Home page of TCGA
UCSC Cancer Genomics Browser saves Cancer genome and clinical data. The platform collects a variety of information of samples, including gene expression level, CNA, pathway information and so on. In the UCSC Cancer Genome Browser, users can compare different samples and cancer types and analyze the correlation between genomic variation and phenotype.
Figure 7 Home page of UCSC Cancer Genomics Browser
There are a large number of mutations in the genome of tumor cells, including chromosomal structure variation, CNA, gene fusion and SNP. Copy number changes (CNAs) contribute significantly to the pathogenesis and progression of cancer. The summary of the Tumor genome databases is shown in table 2.
Table 2 Tumor genome databases
| Datebase | Description |
|---|---|
| arrayMap | Reference resource for genomic copy number imbalances |
| BioMuta | Integrated sequence feature database |
| CanGEM | Cancer GEnome Mine |
| CasSNP | Copy number alterations of cancer genome from SNP array data |
| CGP | Cancer Genome Project |
ArrayMap provides pre-processed tumor genomic microarray data and CNA profiles.
In ArrayMap, users can search for samples of their own interest and analyze the CNA on the gene or genomic fragment. You can also select two samples to compare the difference in CNA between the two.
Figure 8 Home page of ArrayMap
The BioMuta database stores non-synonymous SNP variants of genes in cancer cells, which affect the normal function of genes. Data in the BioMuta were obtained from COSMIC, ClinVar, UniProtKB and some literatures. Users can search for genes of interest and obtain the mutation site and its distribution frequency in cancer cells.

Figure 9 Home page of BioMuta
CanGEM is a public, web-based database for quantitative microarray data and clinical tumor sample data. It mainly uses the arrayCGH microarray to discover the gene copy number variation.
Figure 10 Home page of CanGEM
CaSNP is a web-based database that collects copy number change data based on SNP microarray and provides query services.
CGP provides CNA and genotype information in tumors, and also provides some software to identify mutations and CNA, such as BioView, GRAFT, etc. The main goal of the database is to identify somatic mutations using human genome sequences and high-throughput mutagenesis detection techniques, so as to discover important genes in human tumorigenesis.
Figure 11 Home page of CGP
DNA methylation modification is an important form of epigenetics, which regulates the transcription level of genes and plays an important role in maintaining the normal function of cells. Changes in DNA methylation patterns may lead to cancer. The summary of the Tumor DNA methylation databases is shown in table 3.
Table 3 Tumor DNA methylation databases
| Datebase | Description |
|---|---|
| DiseaseMeth | Human disease methylation database |
| MENT | Methylation and expression database of normal and tumor tissues |
| MethDB | Common resource for epigenetic phenomenon |
| MethHC | DNA methylation and gene expression in human cancer |
| MethyCancer | Next-generation sequencing single-cytosine-resolution DNA methylatio |
DiseaseMeth is a human disease methylation database that covers diseases such as cancer, neurodevelopment and degenerative diseases, and autoimmune diseases. It focus on the effective storage and statistical analysis of DNA methylation data sets of various diseases. In DiseaseMeth, you can compare the methylation relationship between disease and disease, between genes and genes, and between disease and genes.
Figure 12 Home page of DiseaseMeth
MENT is a database of methylation and Expression in both normal and tumor tissues. It collects and integrates DNA methylation and Gene Expression level data from Gene Expression Omnibus (GEO) and TCGA, and associates DNA methylation with Gene Expression level.
Figure 13 Home page of MENT
MethHC is an integrated database containing large amounts of DNA methylation data and mRNA/microRNA expression profiles in human cancers. The data could help researchers determine epigenetic patterns.
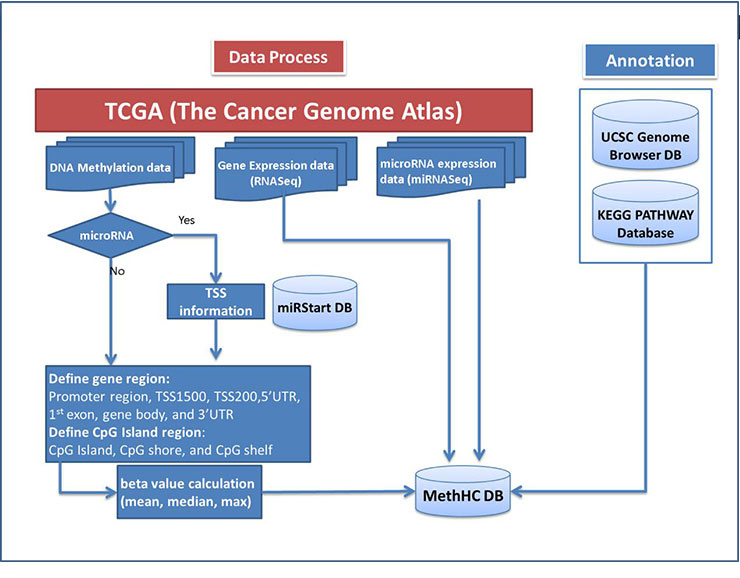
Figure 14. Data generation flow of MethHC[17]
MethHC is an integrated database containing large amounts of DNA methylation data and mRNA/microRNA expression profiles in human cancers. The data could help researchers determine epigenetic patterns.
In addition to the above database for cancer genome methylation, there are other methylation databases: MethDB and NGSmethDB.
MethDB is an early database of DNA methylation, mainly focusing on the influence of environmental factors on methylation.
NGSmethDB is based on high-throughput sequencing data for methylation.
Compared with normal cells, tumor cells have a stronger ability to grow and reproduce, and are active in life. Therefore, there are great differences in gene transcription levels and patterns between tumor cells and normal cells.
Table 4 Tumor transcriptome databases
| Datebase | Description |
|---|---|
| ArrayExpress | Microarray gene expression data |
| ChiTaRS | Chimeric transcripts and RNA-sequencing data |
| GEO | Gene Expression Omnibus |
| miRCancer | MicroRNA cancer association database |
| Oncomine | Cancer microarray database |
| OncomiRDB | Experimentally verified oncogenic and tumor-suppressive microRNAs |
| SomamiR | Somatic mutations impacting microRNA function in cancer |
ArrayExpress is one of the major international knowledgebase for functional genomic experiments based on microarrays and high-throughput sequencing (HTS). Part of the data is submitted directly to ArrayExpress, and the other part is imported from GEO.
Figure 15 Home page of ArrayExpress
ChiTaRS is a database containing chimeric transcripts and RNA-Seq data. Currently, the ChiTaRS database is used to study the identity and incidence of specific fusions of transcripts that may result in a chimeric RNA with novel biological function.

Figure 16 Home page of ChiTaRS
GEO was established by the National Center for Biotechnology Information (NCBI),Home page of ChiTaRS and it’s initial goal was to store high-throughput gene expression data generated primarily by microarray technology as a common repository. In addition, the database also includes comparative genome analysis, chromatin immunoprecipitation analysis, non-coding RNA analysis, SNP genotyping and genomic methylation status analysis.
Figure 17 Home page of GEO
MiRCancer provides a collection of miRNA and their expression in a variety of tumors. MiRCancer data are based on results extracted from literature. All canceration associations of miRNA were confirmed manually after automatic extraction.
Oncomine is a bioinformatics program designed to collect, standardize, analyze and provide cancer transcriptome data to the biomedical research community.
Unlike other microarray repositories, Oncomine can automatically computes differential expression profiles for cancer types and subtypes so that it can easily query for genes or pathology of interest.
Figure 18 Home page of Oncomine
OncomiRDB focuses on the collection of cancer-related miRNA targets. OncomiRDB mainly collects and annotates experimentally verified miRNA information that can promote or inhibit cancer. All data of this database is collected and organized manually.
OncomiRDB is a highly reliable reference resource for studying target genes regulated by miRNA and tumor cell processes.
The SomamiR database mainly collects mutations on miRNA and its target sequences. The purpose is to investigate the effects of somatic and germ line mutations on miRNA function in cancer. In addition, the database also provided tumor-related genes and their involved pathways with somatic mutations of miRNA target sequences.
Figure 19 Home page of SomamiR
Protein is the main undertaker of life activities. Protein structure variation, protein modification and protein content change are important factors that lead to cell growth and metabolism.
Table 5 Tumor proteome databases
| Datebase | Description |
|---|---|
| Cancer3D | Cancer mutations and protein structures |
| CancerPPD | Anticancer peptides and proteins |
| CanProVar | Cancer Proteome Variation Database |
| CPTAC | Clinical Proteomic Tumor Analysis Consortium |
| dbDEPC | Differentially expressed proteins in human cancers |
Cancer3D database integrates somatic cell missense mutation information from TCGA and CCLE to analyze its impact on protein function on the level of protein structure. Through E-driver and E-drug algorithms, the database helps users analyze the distribution pattern of mutations and their relationship with changes in Drug activity.
CancerPPD is a repository of anti-cancer peptides (ACPs) and anti-cancer proteins that are very useful in designing peptide-based anticancer therapies.
In CancerPPD, detailed information is provided for each entry, such as the source of the peptide, the nature of the peptide, anticancer activity, N- and C-terminal modifications, conformation, and the like.
Figure 20 Home page of CancerPPD
The CanProVar database integrates protein sequence variation information from a variety of public sources, with a focus on cancer-related variability. The data in CanProVar is mainly derived from databases such as TCGA, COSMIC, OMIM, HPI, and some research literature.
CPTAC integrates genomic and proteomic data to identify and describe all proteins in tumor tissue and normal tissue, and to identify candidate proteins that can be used as tumor biomarkers.
DbDEPC is a database that specifically collects differentially expressed proteins from tumor samples. It allows researchers to search for changes in proteins they are interested in in certain cancers, and to link changes in protein expression to abnormalities in other gene levels.
Table 6 Tumor-associated gene databases
| Datebase | Description |
|---|---|
| DriverDB | Exome sequencing database for cancer driver gene |
| NCG | Network of Cancer Genes |
| TP53MULTLoad | TP53 mutation database |
| UMD TP53 | TP53 database |
DriverDB gathered a large amount of exome-seq data from databases such as TCGA, ICGC, TARGET, and so on, and provided a visualization of mutation information based on different aspects. These visualizations will help users quickly understand the relationships between the driver genes.
DriverDB providing three levels of biological explanation: genetic oncology, pathways, and protein/genetic interactions.
Figure 21 Home page of DriverDB
The cancer gene network (NCG) has been working to gather information about known and candidate cancer genes for human screening.
Users can obtain the gene related function and disease annotation information, mutation information, expression profile, miRNA and protein interaction relationship, etc., and visualize the miRNA regulatory relationship and protein interaction network.
It is a manually collected resource center for TP53 mutations and mutants, containing the UMDTP53 database and information related to TP53.It can be used either as an easy-to-use flat file or as a new multiplatform analysis software for analyzing various aspects of TP53 mutations.
Figure 22 Home page of TP53MULTLoad
Table 7 Tumor and drug databases
| Datebase | Description |
|---|---|
| CancerDR | Cancer drug resistance database |
| CancerResource | Cancer-relevant proteins and compound interactions |
| canSAR | Cancer research and drug discovery knowledgebase |
| GDSC | Genomics of Drug Sensitivity in Cancer |
| Platinum | Mutations on structurally defined protein-ligand complexes |
Drug target mutation is one of the main causes of acquired drug resistance. A full understanding of these drug target mutations will help design effective personalized therapies.
CancerDR is an attempt to develop personalized drugs for cancer treatment.
CancerDR collected 148 cancer-fighting drugs and their pharmacological status in 952 cell lines.
Figure 23 Various applications of CancerDR
This picture comes from the literature Cancer Drug Resistance Database [33]
CancerResource collects information on a large number of compounds and their targets through literature mining and integration of various data sources. This will contribute to the development and research of precision medicine.
CancerResource database allows you to get detailed information on compounds and targets, including expression profiles and related data source links.
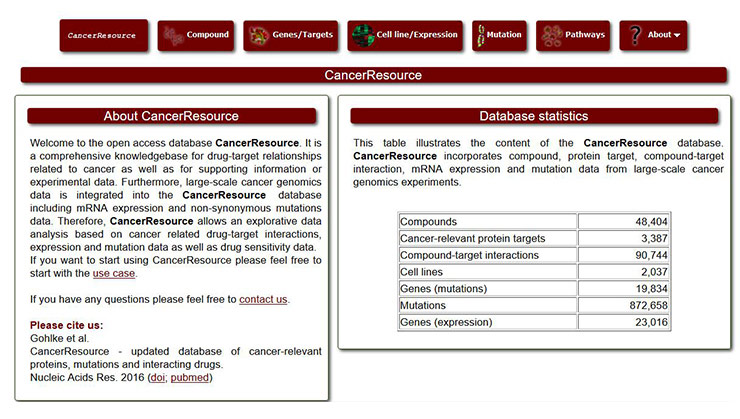
Figure 24 Home page of CancerResource
canSAR is a public comprehensive cancer knowledge base that supports cancer translational research and drug discovery. canSAR integrates data from ArrayExpress, UniProt, COSMIC and other 11 data sources. The database contains data of various types including biology, pharmacology, chemistry, structural biology and protein interaction networks.

Figure 25 Home page of canSAR
GDSC is a database of drug sensitivity and drug response molecular markers for cancer cells. The database includes oncogene mutation information such as oncogene point mutations, gene amplification and loss, tissue types, and expression profiles.
GDSC provides a unique resource that combines large drug sensitivity and genomic data sets to facilitate the discovery of new therapeutic biomarkers for cancer treatment.
Figure 26 Home page of GDSC
Platinum is a database developed to study and understand the effects of missense mutations on ligand-proteome interactions. It is a database that collects information on drug resistance.
The Platinum database correlates protein structure mutations with ligand affinities to help study disease resistance caused by mutations.
Figure 27 Home page of Platinum
References
[1] Samur M K, Yan Z, Wang X, et al. canEvolve: A Web Portal for Integrative Oncogenomics [J]. PLOS ONE, 2013, 8.
[2] Gao J, Aksoy B A, Dogrusoz U, et al. Integrative Analysis of Complex Cancer Genomics and Clinical Profiles Using the cBioPortal [J]. Science Signaling, 2013, 6(269): pl1-pl1.
[3] Strausberg R L, Buetow K H, Emmert-Buck M R, et al. The Cancer Genome Anatomy Project: building an annotated gene index [J]. Trends in Genetics Tig, 2000, 16(3): 103-106.
[4] Wilks C, Cline M S, Weiler E, et al. The Cancer Genomics Hub (CGHub): overcoming cancer through the power of torrential data [J]. Database, 2014, 2014: bau093-bau093.
[5] Zhang J, Finney R P, Rowe W, et al. Systematic analysis of genetic alterations in tumors using Cancer Genome WorkBench (CGWB) [J]. Genome Research, 2007, 17(7): 1111-1117.
[6] Forbes S A, Beare D, Gunasekaran P, et al. COSMIC: exploring the world’s knowledge of somatic mutations in human cancer [J]. Nucleic Acids Research, 2015, 43(D1): D805-D811.
[7] Banks R, LopezOtín, Carlos. International network of cancer genome projects [J]. Nature, 2010, 464(7291): 993-998.
[8] Chang K, Creighton C J, Davis C, et al. The Cancer Genome Atlas Pan-Cancer analysis project [J]. Nature Genetics, 2013, 45(10): 1113-1120.
[9] Benz S C, Craft B, Szeto C, et al. The UCSC Cancer Genomics Browser: update 2011 [J]. Nucleic Acids Research, 2013, 43(Database issue): 812-7.
[10] Cai H, Gupta S, Rath P, et al. ArrayMap 2014: An updated cancer genome resource [J]. Nucleic Acids Research, 2014, 43(D1).
[11] Wu T J, Shamsaddini A, Pan Y, et al. A framework for organizing cancer-related variations from existing databases, publications and NGS data using a High-performance Integrated Virtual Environment (HIVE) [J]. Database, 2014, 2014: bau022-bau022.
[12] Scheinin I, Myllykangas S, Borze I, et alet al
[13] Cao Q, Zhou M, Wang X, et al. CaSNP: a database for interrogating copy number alterations of cancer genome from SNP array data [J]. Nucleic Acids Research, 2011, 39(Database issue): D968.
[14] Timms B. Cancer genome project to start [J]. European Journal of Cancer, 2000, 36(6): 687.
[15] Lv J, Liu H, Su J, et al. DiseaseMeth: a human disease methylation database [J]. Nucleic Acids Research, 2012, 40(Databaseissue): 1030-5.
[16] Baek S J, Yang S, Kang T W, et al. MENT: Methylation and expression database of normal and tumor tissues [J]. Gene, 2013, 518(1): 194-200.
[17] Huang W Y, Hsu S D, Huang H Y, et al. MethHC: a database of DNA methylation and gene expression in human cancer [J]. Nucleic Acids Research, 2015, 43(D1): D856-D861.
[18] He X, Chang S, Zhang J, et al. MethyCancer: the database of human DNA methylation and cancer [J]. Nucleic Acids Research, 2008, 36(Database issue): D836-841.
[19] Kolesnikov N, Hastings E, Keays M, et al. ArrayExpress update--simplifying data submissions [J]. Nucleic Acids Research, 2015, 43(D1): D1113-D1116.
[20] Frenkel-Morgenstern M, Gorohovski A, Vucenovic D, et al. ChiTaRS 2.1--an improved database of the chimeric transcripts and RNA-seq data with novel sense-antisense chimeric RNA transcripts [J]. Nucleic Acids Research, 2015, 43(D1): D68-D75.
[21] Barrett T, Troup D B, Wilhite S E, et al. NCBI GEO: archive for functional genomics data sets - 10years on [J]. Nucleic Acids Research, 2012, 39(D1).
[22] Xie B, Ding Q, Han H, et al. miRCancer: a microRNA-cancer association database constructed by text mining on literature [J]. Bioinformatics, 2013, 29(5): 638-644.
[23] Rhodes D R, Kalyana-Sundaram S, Mahavisno V, et al. Oncomine 3.0: Genes, Pathways, and Networks in a Collection of 18,000 Cancer Gene Expression Profiles [J]. Neoplasia, 2007, 9(2): 166-180.
[24] Wang D, Gu J, Wang T, et al. OncomiRDB: a database for the experimentally verified oncogenic and tumor-suppressive microRNAs [J]. Bioinformatics, 2014, 30(15): 2237-2238.
[25] Bhattacharya A, Ziebarth J D, Cui Y. SomamiR: A database for somatic mutations impacting microRNA function in cancer [J]. Nucleic Acids Research, 2012, 41(Database issue).
[26] Porta-Pardo E, Hrabe T, Godzik A. Cancer3D: understanding cancer mutations through protein structures [J]. Nucleic Acids Research, 2015, 43(D1): D968-D973.
[27] Tyagi A, Tuknait A, Anand P, et al. CancerPPD: a database of anticancer peptides and proteins [J]. Nucleic Acids Research, 2015, 43(D1): D837-D843.
[28] Li J, Duncan D T, Zhang B. CanProVar: a human cancer proteome variation database [J]. Human Mutation, 2010, 31(3): 219-228.
[29] Ellis M J, Gillette M, Carr S A, et al. Connecting genomic alterations to cancer biology with proteomics: The NCI clinical proteomic tumor analysis consortium [J]. Cancer Discovery, 2013, 3(10): 1108-1112.
[30] He Y, Zhang M, Ju Y, et al. dbDEPC 2.0: updated database of differentially expressed proteins in human cancers [J]. Nucleic Acids Research, 2012, 40(D1): D964-D971.
[31] An O, Pendino V, D’Antonio M, et al. NCG 4.0: the network of cancer genes in the era of massive mutational screenings of cancer genomes [J]. Database, 2014, 2014: bau015-bau015.
[32] Leroy B, Fournier J L, Ishioka C, et al. The TP53 website: an integrative resource centre for the TP53 mutation database and TP53 mutant analysis [J]. Nucleic Acids Research, 2013, 41(Database issue): D962.
[33] Kumar R, Chaudhary K, Gupta S, et al. CancerDR: Cancer Drug Resistance Database [J]. Scientific Reports, 2013, 3: 1445.
[34] Ahmed J, Meinel T, Dunkel M, et al. CancerResource: a comprehensive database of cancer-relevant proteins and compound interactions supported by experimental knowledge [J]. Nucleic Acids Research, 2011, 39(Database issue): 960-7.
[35] Bulusu K C, Tym J E, Coker E A, et al. canSAR: updated cancer research and drug discovery knowledgebase [J]. Nucleic Acids Research, 2014, 42(D1): D1040-D1047.
[36] Yang W, Soares J, Greninger P, et al. Genomics of Drug Sensitivity in Cancer (GDSC): a resource for therapeutic biomarker discovery in cancer cells [J]. Nucleic Acids Research, 2013, 41(Database issue): D955.
[37] Pires D E V, Blundell T L, Ascher D B. Platinum: A database of experimentally measured effects of mutations on structurally defined protein-ligand complexes [J]. Nucleic Acids Research, 2014, 43(D1).


Comments
Leave a Comment