Call us
301-363-4651 (Available 9 a.m. to 5 p.m. CST from Monday to Friday)
Recombinant protein expression is a cornerstone of biotechnology. It powers drug development, studies in structural biology, and enzyme production. But let’s be honest, how many times have you stared at a gel showing no protein band and wanted to scream? Why does your protein keep ending up in inclusion bodies? Let's break down the science, share battle-tested fixes, and turn frustration into results.
This article will give you a clear roadmap that breaks down what recombinant protein expression is—including the five major expression platforms and their pros and cons—along with common challenges and how to troubleshoot them. It also highlights powerful open-source tools to help guide your project every step of the way.
Table of Contents
1. What Is Recombinant Protein Expression?
2. Typical Challenges in Recombinant Protein Expression and Corresponding Optimization Strategies
3. Open-Source Protein Information & Structure Prediction Databases
Recombinant protein expression is the process of producing a protein by inserting the gene encoding it into a host organism (like E. coli or yeast) via an expression vector and then expressing the gene. This enables researchers and companies to synthesize important proteins that are difficult or impossible to extract naturally.
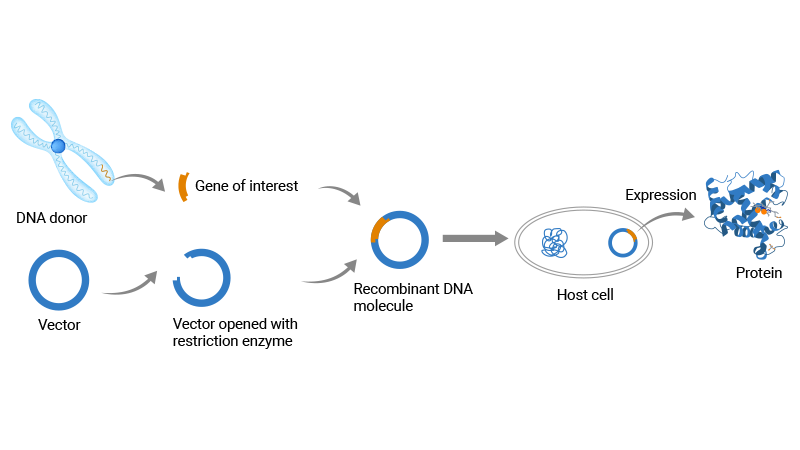
Figure 1. The workflow of recombinant protein expression
Why does recombinant protein expression matter so much? Proteins are the most biological macromolecules within cells and play crucial roles in various biological processes during life activities. Recombinant protein expression technology promotes drug discovery, allowing the production of therapeutics like insulin and monoclonal antibodies. It also fuels industrial enzyme supply and structural studies that reveal protein functions.
When expressing a protein, there are a series of questions come to mind. For example, is the target protein to be expressed prokaryotic or eukaryotic?
Does the protein application require post-translational modifications (PTMs)?
Which type of glycosylation is required?
Does the protein contain disulfide bonds?
Do you require higher production yields/multiple expression rounds?
...
Don't be anxious. Here introduce five recombinant protein expression systems. Each has its perks and limitations. You can choose the right expression system for the specific protein.
| E.coli expression system | Pichia pastoris expression system | Baculovirus Insect expression system | Mammalian Cell expression system | Cell free expression system | |
|---|---|---|---|---|---|
| Advantages |
|
|
|
|
|
| Limitations |
|
|
|
|
|
| Suitable Proteins |
|
|
|
|
|
Despite its promise, recombinant protein expression often fails. Low yields, misfolded proteins, and toxic effects on host cells plague researchers. Ever spent weeks optimizing a construct only to get insoluble aggregates? What causes these problems? And how can we fix them? You are not alone. Let’s address that.
No expression system is perfect. Here are several key challenges encountered during recombinant protein expression and corresponding optimization strategies.
| Challenges | Potential Causes | Optimization Strategies |
|---|---|---|
| Low expression | ① Weak or inappropriate promoter ② Unstable or rapidly degraded protein ③ Poorly designed ribosome-binding site (RBS) and insufficient translation initiation efficiency ④ Low plasmid copy number ⑤ Gene sequence (codon bias) ⑥ Lack of chaperone and aggregation ⑦ Suboptimal culture conditions or induction timing |
① Use strong promoters (e.g., T7 for bacteria, or inducible promoters like lac, araBAD) ② Use protease-deficient host strains (e.g., E. coli BL21(DE3) lacking Lon/T proteases or add stabilizing agents (e.g., glycerol, sorbitol) to culture media ③ Optimize RBS sequence using computational tools (e.g., RBS Calculator, Geneious) or use commercial expression vectors with pre-optimized RBS sequences ④ Switch to high-copy-number plasmids (e.g., pET, pUC origin) or use plasmid stabilization systems (e.g., par loci, antibiotic selection) ⑤ Introducing synonymous mutations with the most abundant ones in the host to encode amino acid or replace rare codons with host-preferred ones and consider codon combination or adjust GC content ⑥ Co-express molecular chaperones (e.g., GroEL/GroES, TF) or use chaperone-rich host strains (e.g., E. coli BL21(DE3)pLysS, Origami) ⑦ Optimize induction temperature (e.g., lower temperatures for stability) or adjust induction timing (e.g., mid-log phase induction), or use autoinduction media or optimize inducer concentration (e.g., IPTG, arabinose) |
| Misfolding | ① Lack of host chaperones ② Improper disulfide bond formation ③ Aggregation-prone sequences ④ Rapid expression rates |
① Co-express molecular chaperones (e.g., GroEL/GroES, DnaK/DnaJ) or use chaperone-rich host strains (e.g., E. coli BL21(DE3)pGro7, Origami, or Rosetta-gami) ② Use strains with oxidizing cytoplasm (e.g., SHuffle E. coli for eukaryotic disulfide bonds) or co-express disulfide isomerases (e.g., DsbC, PDI in eukaryotic systems) ③ Introduce solubility-enhancing tags (e.g., MBP, GST, SUMO) or mutate aggregation-prone regions (e.g., replace hydrophobic residues with polar/charged residues) ④ Lower expression temperature (e.g., 16–25°C) to slow translation and allow proper folding or weaker promoters or inducible systems (e.g., araBAD promoter with arabinose titration) |
| Poor protein solubility | ① Hydrophobic regions ② Lack of solubility-enhancing tags ③ Protein aggregation ④ Inadequate buffer conditions |
① Co-expression with molecular chaperones (e.g., GroEL/GroES) to assist folding or mutate hydrophobic residues to reduce aggregation (e.g., replace with polar/charged residues) or add detergents (e.g., Triton X-100, CHAPS) or cosolvents (e.g., glycerol, PEG) to shield hydrophobic regions ② Use of solubility-enhancing fusion tags like MBP, GST, or SUMO ③ Reduce expression rate by lowering induction temperature (16–25°C) or employ chaperone-rich strains (e.g., E. coli BL21(DE3)pLysS, Rosetta-gami) ④ Screen solubility-enhancing buffers (e.g., arginine, glycerol, detergents) |
| Inclusion body formation | ① Overexpression and rapid expression ② Insufficient folding capacity ③ Lack of chaperone and aggregation ④ Phssical, chemical, and structural characteristics of the protein [3-5] ⑤Inappropriate culture/induction conditions |
① Reduce expression rate by lowering temperature (16–25°C) or use lower inducer concentrations (e.g., 0.1–0.5 mM IPTG) or autoinduction media ② Co-express foldases (e.g., DsbA/DsbC for disulfide bonds) or chaperones (e.g., GroEL/GroES) or use strains with enhanced folding machinery (e.g., SHuffle for disulfide bonds, Origami for redox balance) ③ Co-express aggregation-suppressing chaperones (e.g., Trigger Factor, Hsp70) or use strains with upregulated chaperone systems (e.g., E. coli C41/C43) ④ Add solubility-enhancing tags (e.g., MBP, GST, SUMO) or modify buffer conditions (e.g., include arginine, detergents, or reducing agents like DTT) ⑤ Optimize temperature (e.g., 18–25°C for slow folding), or adjust pH (e.g., neutral pH for stability), or use osmolytes (e.g., sorbitol, betaine) to stabilize folding intermediates, or shorten induction time to limit overexpression |
Here are two representative vectors and their main features.
| Representative Vectors | Features |
|---|---|
| pET22b(+)+BL21(DE3) strain | ① T7 promotor ② IPTG-inducible expression with adjustable expression levels ③ C-teminus: 6*His tag ④ N-terminus: contains PelB signal peptide sequence, which localizes the expressed target protein to the periplasmic space |
| pPIC9K-SOMOSTAR plasmid+GS115 strain | ① AOX1 strong promotor ② Alpha-factor secretion signal for sufficient secretion ③ SUMOSTAR fusion protein for expression improvement ④ His tag ⑤ simple to use, stable replication and expression of foreign genes in Pichia pastoris, easy amplification in E.coli for plasmid preparation and purification |
There is a lot of preparatory work to be done before recombinant protein expression. We can use the database to get the protein information and also to perform the protein structure prediction.
Here are some open-source databases and tools available for protein information and structure prediction.
| Tools | Description |
|---|---|
| BLASTP | Amino acid sequence alignment: compares protein sequences against databases to identify similarities; helps in predicting protein function, identifying conserved domains, and inferring evolutionary relationships. |
| Uniprot | A comprehensive protein database that provides detailed information about protein sequences, functions, and annotations. |
| Swiss-Prot | A high-quality, manually annotated, non-redundant dataset with annotations derived from literature or verified analyses; particularly useful for functional information, conserved domains, and known PTMs. |
| Expasy-ProtParam | Determines physicochemical properties of proteins, including molecular weight, theoretical isoelectric point, amino acid composition, atomic composition, extinction coefficient, estimated half-life, instability index, and hydrophobic moment, etc |
| Alphafold | Predicts 3D protein structures with high accuracy. |
| AIUPred | Predicts intrinsically disordered regions in proteins (regions lacking stable structure and highly variable); helpful to identify flexible or aggregation-prone zones. |
| SignalP (DTU Health Tech) | Predicts the presence and location of signal peptides in protein sequence; essential for studying protein secretion and localization. |
| TMHMM-2.0 (DTU Health Tech) | Predicts transmembrane domains in proteins; widely used to identify membrane proteins and understand their topology, which is crucial for studying their function and interactions. |
These resources enables informed decisions on construct design, tag placement, and expression system choice, boosting confidence and cutting trial-and-error.
Recombinant protein expression is a powerful, yet intricate technology. It is fundamental for modern medicine, from producing lifesaving drugs to unraveling protein function. However, challenges abound—poor expression, misfolding, inclusion body formation, and more. The good news? Strategic choices in expression system, vector design, culture conditions, and optimization tactics radically improve outcomes.
Using these insights, you’ll get clear, actionable advice without jargon or vague theory, enabling faster troubleshooting by pinpointing exactly where expression may fail. This also leads to smarter planning, helping you avoid pitfalls that waste time and resources. Ultimately, you'll gain confidence in selecting a system that’s precisely tailored to your protein’s specific needs.
Further Reading:
Production of Recombinant Protein
CUSABIO's Five Expression Systems
How to choose a suitable expression vector?
Protein Tags: A Comprehensive Overview
What is a His Tag? A Guide from Definition to Applications
What is Myc Tag: Definition, Function, Applications & Comparison with Other Epitope Tags
How to Choose the Right Recombinant Protein for Your Experimental Model?
References
[1] Rosano, G. L., & Ceccarelli, E. A. (2014). Recombinant protein expression in Escherichia coli: Advances and challenges [J]. Frontiers in Microbiology, 5, 79503.
[2] Tripathi, N. K., & Shrivastava, A. (2019). Recent Developments in Bioprocessing of Recombinant Proteins: Expression Hosts and Process Development [J]. Frontiers in Bioengineering and Biotechnology, 7, 420.
[3] Bhatwa, A., Wang, W., Hassan, Y. I., Abraham, N., Li, Z., & Zhou, T. (2021). Challenges Associated With the Formation of Recombinant Protein Inclusion Bodies in Escherichia coli and Strategies to Address Them for Industrial Applications [J]. Frontiers in Bioengineering and Biotechnology, 9, 630551.
[4] Dyson M. R., Shadbolt S. P., Vincent K. J., Perera R. L., McCafferty J. (2004). Production of soluble mammalian proteins in Escherichia coli: identification of protein features that correlate with successful expression [J]. BMC Biotechnol. 4:32.
[5] Goh C. S., Lan N., et al. (2004). Mining the structural genomics pipeline: identification of protein properties that affect high-throughput experimental analysis [J]. J. Mol. Biol. 336 115–130.


Comments
Leave a Comment